Spring Boot + Kotlin + Spring AI로 간단하게 만든 AI 기반 운영 자동화 도구 개발 과정
배경
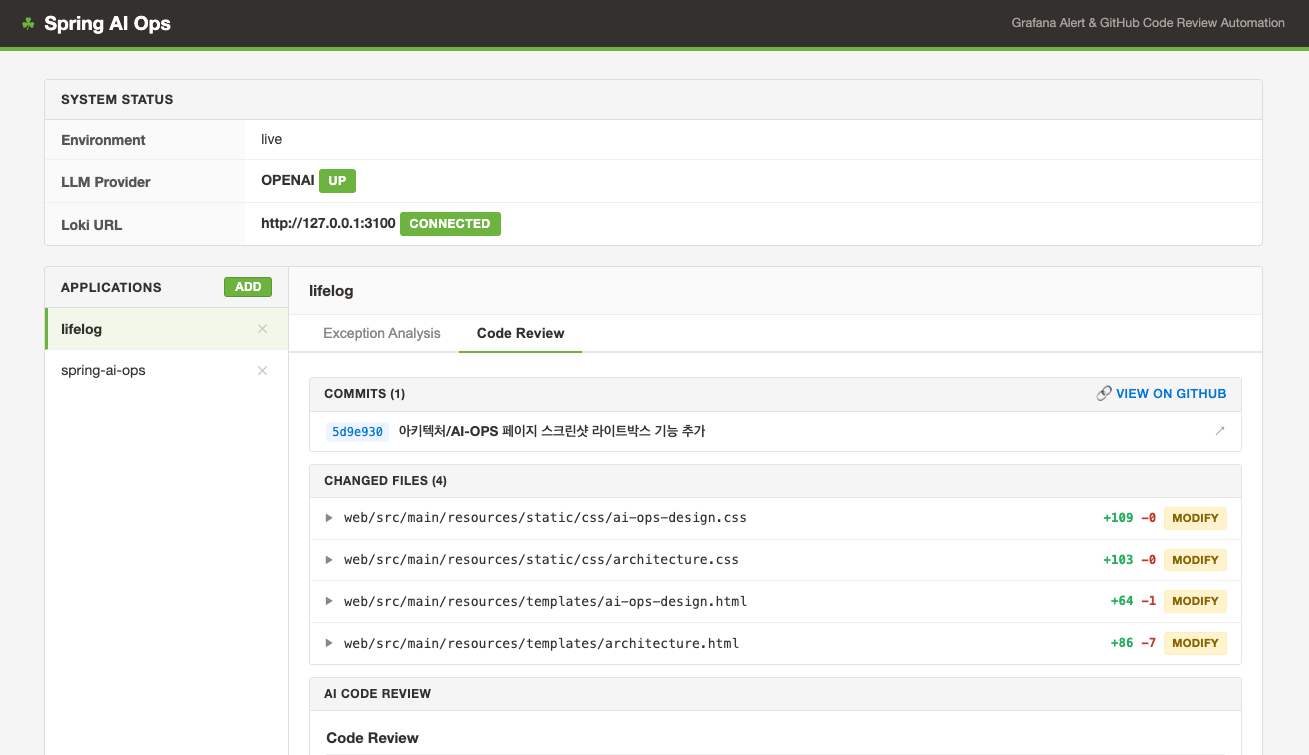
서비스를 운영하다 보면 Grafana 알림이 울릴 때마다 로그를 뒤지고, GitHub push 후에 코드 리뷰를 기다리는 시간이 꽤 소모된다. 최근에 AI 컨퍼런스에서 AI와 연계된 Observability의 사례를 가장 인상깊게 보기도 했기에 한번 직접 구현해볼까? 라는 생각에서 Spring AI Ops라는 이름으로 작은 토이 프로젝트를 만들어 봤다.
핵심 기능은 두 가지이다.
- Grafana Alerting → Loki 로그 조회 → AI 장애 분석
- GitHub git push → commit diff 조회 → AI 코드 리뷰
분석 결과는 WebSocket으로 브라우저에 실시간 전달되도록 구현하였다.
Stack
| 기술 | 선택 이유 |
|---|---|
| Spring Boot 3.4 + Kotlin | 익숙한 Stack, Kotlin의 간결한 DSL과 data class |
| Spring AI 1.1.0 | OpenAI/Anthropic 추상화, 동일한 ChatModel 인터페이스 |
| Redis | RDB 없이 간단하게 유지, TTL로 자동 만료 |
| Java 21 Virtual Thread | LLM 호출(수 초~수십 초)을 블로킹 없이 처리 |
| STOMP WebSocket | 분석 완료 즉시 브라우저에 push |
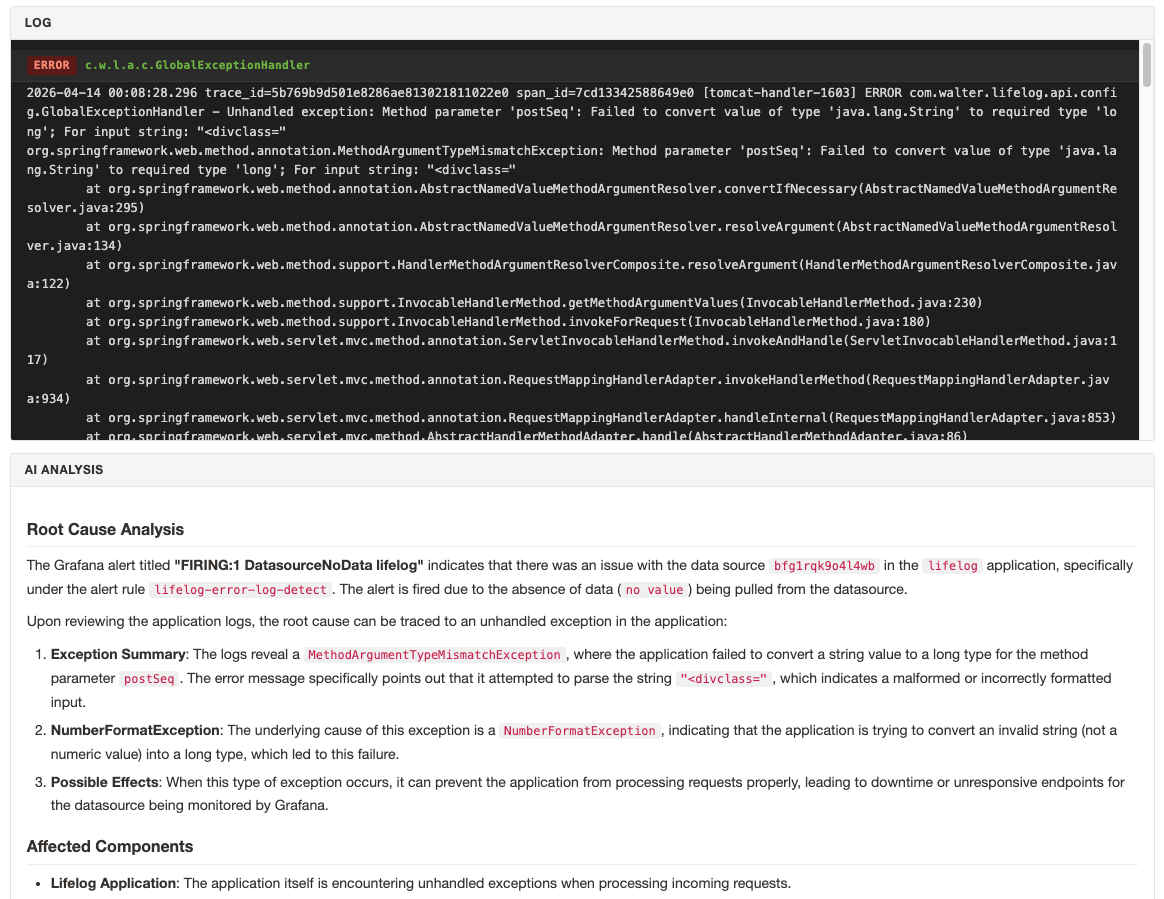
주요 기능 1 — Grafana → Loki → LLM 장애 분석
전체 흐름
Grafana Alert 발생
│
▼
POST /webhook/grafana/{application}
└─ CompletableFuture.runAsync (Virtual Thread)
│
├─ 1. GrafanaAlert에서 Loki 스트림 셀렉터 구성
│ {job="my-app", namespace="prod", pod="api-xyz"}
│
├─ 2. 시간 범위 계산
│ start = startsAt − 5분 버퍼 (Unix nanoseconds)
│ end = endsAt (zero-value "0001-..." 이면 현재 시각)
│
├─ 3. Loki query_range API 호출
│
├─ 4. LLM에 분석 요청
│ System: "expert in application errors and logs"
│ User: Alert 컨텍스트 + 로그 라인
│ → 근본 원인 / 영향 범위 / 조치 방법 (markdown)
│
├─ 5. Redis에 AnalyzeFiringRecord 저장 (TTL: 5일)
│
└─ 6. /topic/firing 으로 WebSocket push설계 포인트: Webhook은 즉시 응답
LLM 호출은 수 초에서 수십 초가 걸린다. Grafana는 webhook 응답 타임아웃이 짧기 때문에, Controller는 즉시 ACCEPTED를 반환하고 분석은 비동기로 처리한다.
@PostMapping(value = ["/grafana", "/grafana/{application}"])
fun grafanaAlert(
@RequestBody request: GrafanaAlertingRequest,
@PathVariable application: String?
): GrafanaAlertingResponse {
if (request.isResolved()) {
return GrafanaAlertingResponse.of(AlertingStatus.RESOLVED)
}
CompletableFuture.runAsync({ analyzeFacade.analyzeFiring(request, application) }, executor)
return GrafanaAlertingResponse.of(AlertingStatus.ACCEPTED)
}executor는 Executors.newVirtualThreadPerTaskExecutor()로 만든 Virtual Thread executor이다. LLM 호출처럼 I/O 대기가 긴 작업에서 플랫폼 스레드를 낭비하지 않는다.
@Bean(TaskExecutionAutoConfiguration.APPLICATION_TASK_EXECUTOR_BEAN_NAME)
fun applicationTaskExecutor(): AsyncTaskExecutor =
TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor())설계 포인트: Prometheus 레이블 ↔ Loki 레이블 매핑
Grafana 알림 페이로드의 labels에는 Prometheus 메트릭 레이블이 들어 있다. Loki 스트림 레이블과 동일한 키를 공유할 때만 자동으로 로그를 조회할 수 있다. GrafanaAlert에서 허용 키만 필터링해 스트림 셀렉터를 만든다.
private val LOKI_LABEL_KEYS = setOf(
"job", "instance", "namespace", "pod", "container",
"service_name", "app", "cluster", "env", "environment", "application"
)
fun lokiLabels(): Map<String, String> = labels.filterKeys { it in LOKI_LABEL_KEYS }Promtail이나 logback-spring.xml에서 Loki4jAppender를 이용하여 Loki로 로그를 전송할 때 레이블 세트를 Prometheus와 동일하게 맞추지 않으면 조회 결과가 비어 버린다. 처음에 이 부분을 간과해서 로그가 항상 빈 채로 LLM에 전달되는 문제가 있었는데, 이는 하단 트러블슈팅 섹션에서 적어놓았다.
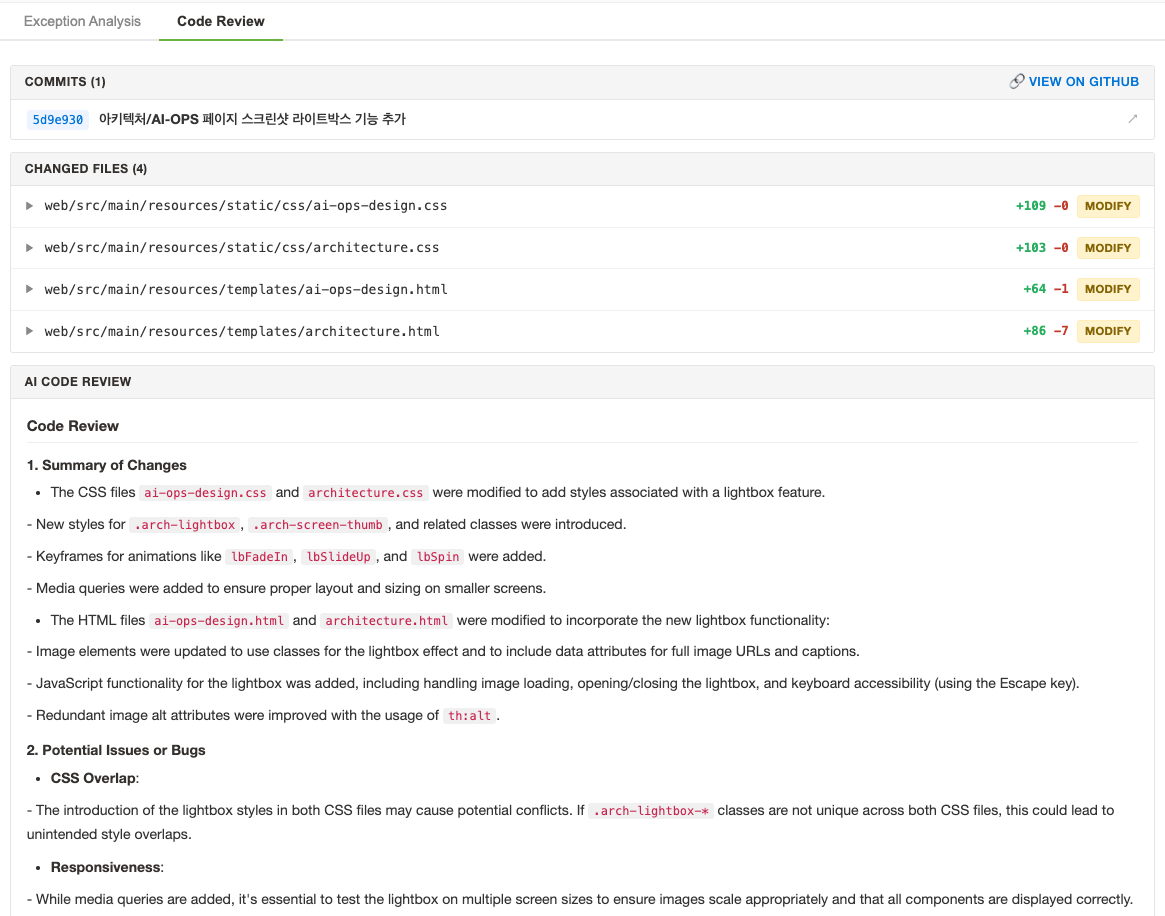
주요 기능 2 — GitHub push → LLM 코드 리뷰
전체 흐름
git push 이벤트
│
▼
POST /webhook/github/{application}
└─ CompletableFuture.runAsync (Virtual Thread)
│
├─ 1. before/after SHA 추출
│ before == "0000...0000" (첫 push) → GET /commits/{sha}
│ otherwise → GET /compare/{base}...{head}
│
├─ 2. 변경 파일별 diff(patch) 수집
│
├─ 3. LLM에 코드 리뷰 요청
│ System: "expert code reviewer"
│ User: 파일별 diff
│ → 변경 요약 / 잠재 이슈 / 보안 / 개선 제안 (markdown)
│
├─ 4. Redis에 CodeReviewRecord 저장 (TTL: 5일)
│
└─ 5. /topic/commit 으로 WebSocket push설계 포인트: 첫 push vs 일반 push 분기
GitHub는 새 브랜치의 첫 push 때 before SHA를 0000000000000000000000000000000000000000으로 보낸다. 이 경우 Compare API를 쓸 수 없어 단일 commit API로 분기 처리한다.
private fun createGithubUrl(request: GithubPushRequest): String =
when {
request.isNewBranch() -> "${request.repository.htmlUrl}/commit/${request.after}"
else -> "${request.repository.htmlUrl}/compare/${request.before}...${request.after}"
}
Spring AI AutoConfiguration을 전부 껐다.

Spring AI는 application.yml에 spring.ai.openai.api-key를 넣으면 자동으로 OpenAiChatModel Bean을 만들어준다. 처음에는 이 방식을 사용했는데 두 가지 문제가 있었다.
- 런타임 전환 불가: OpenAI ↔ Anthropic을 UI에서 바꿀 수 없다. AutoConfiguration은 애플리케이션 시작 시점에 Bean을 고정한다.
- Redis 복원 불가: 재시작 후 Redis에 저장된 API 키와 provider 정보를 읽어
ChatModel을 복원하려면 직접 인스턴스를 생성해야 한다.
결국 모든 Spring AI AutoConfiguration을 spring.autoconfigure.exclude로 비활성화하고, AiModelService에서 ChatModel을 직접 생성한다.
private fun buildChatModel(llm: String, apiKey: String): ChatModel {
val toolCallingManager = ToolCallingManager.builder().build()
val retryTemplate = RetryUtils.DEFAULT_RETRY_TEMPLATE
val observationRegistry = ObservationRegistry.NOOP
return when (llm) {
"openai" -> {
val api = OpenAiApi.builder().apiKey(apiKey).build()
val options = OpenAiChatOptions.builder().model(openAiModel).build()
OpenAiChatModel(api, options, toolCallingManager, retryTemplate, observationRegistry)
}
"anthropic" -> {
val api = AnthropicApi.builder().apiKey(apiKey).build()
val options = AnthropicChatOptions.builder().model(anthropicModel).maxTokens(1024).build()
AnthropicChatModel(api, options, toolCallingManager, retryTemplate, observationRegistry)
}
else -> throw IllegalArgumentException("Unknown LLM provider: $llm")
}
}@Volatile로 선언된 chatModel 필드는 @PostConstruct에서 Redis 값을 읽어 복원되고, UI에서 변경 시 즉시 교체된다.
저장소: RDB 없이 Redis만 사용
분석 결과 저장에 RDB를 쓰지 않았다. 이유는 단순한데 인프라 복잡성을 줄이고 최대한 간단하게 만들기 위해서였다. 그리고 대부분의 경우 운영 이력 데이터는 최신 N건만 의미 있고, 일정 기간이 지나면 자동으로 Fade-Out되는 것 정도로도 충분하다. Redis List + TTL 조합이 딱 맞다.
물론 이 프로젝트를 실무에 쓴다고 하면 결국 RDB를 붙일 것 같기는 하다.
fun listPushWithTtl(key: String, value: String, ttlHours: Long) {
opsForList().leftPush(key, value)
expire(key, ttlHours, TimeUnit.HOURS)
}데이터 보관 기간(data-retention-hours)과 최대 조회 건수(maximum-view-count)는 application.yml로 조정할 수 있다.
트러블슈팅
1. Loki 로그가 항상 비어서 오는 문제
증상: LLM 분석 결과에 항상 "No log data available"이 포함됨.
원인: Prometheus 알림 레이블과 Loki 스트림 레이블이 달랐다. Prometheus에서는 job="lifelog"을 쓰고 있었지만 Promtail에서는 application="lifelog"으로 설정되어 있었다.
해결: Grafana Alerting 설정에서 application 레이블을 추가하여 Alerting 메시지에 application="lifelog"이 포함되게 하고, 이를 가지고 Loki Query에 활용하게 했다. LOKI_LABEL_KEYS 집합에서 허용하는 키를 명시적으로 정의했다.
교훈: Prometheus와 Loki의 레이블 일치는 이 시스템의 전제 조건이다. 레이블 불일치는 무음(silent) 실패로 나타나기 때문에 발견이 늦을 수 있다. 초기 설정 시 Loki 쿼리를 직접 실행해 확인하는 것이 좋다.
2. Spring AI AutoConfiguration Bean 충돌
증상: application.yml에 spring.ai.openai.api-key를 설정하자 OpenAiChatModel 빈이 두 개 생겨 주입 오류 발생.
원인: AutoConfiguration이 만든 Bean과 AiModelService에서 직접 생성한 인스턴스가 동시에 존재.
해결: AutoConfiguration 전체를 spring.autoconfigure.exclude로 비활성화. 이후 AiModelService가 ChatModel의 유일한 생성 및 관리 주체가 됨.
3. WebSocket 수신 후 List에 push 데이터만 표시되는 문제

증상: WebSocket으로 새 분석 결과가 push되면 하단 Firing List / Commit History에 해당 레코드 하나만 보임. 페이지 새로고침 후에야 전체 목록이 나타남.
원인: WebSocket 수신 핸들러(handleFiringRecord, handleCommitRecord)가 받은 레코드를 로컬 배열에 unshift만 하고 있었다. 앱을 처음 선택할 때 API로 목록을 불러오지만, WebSocket 수신 경로에서는 API를 호출하지 않아 로컬 배열에 현재 세션에서 받은 것만 누적됐다.
해결: WebSocket 수신 시 로컬 unshift 대신 list API를 호출해 서버에서 전체 최신 목록을 받아오도록 변경.
async function handleFiringRecord(record) {
const appName = record.application;
// 로컬 unshift 제거 → API에서 최신 목록 전체를 가져옴
await loadFiringList(appName);
appSelectedFiringIdx[appName] = 0;
// ...렌더링
}마무리
- Spring AI의 추상화는 OpenAI와 Anthropic을 동일한 인터페이스로 다룰 수 있어 편리하지만, AutoConfiguration에 의존하면 런타임 전환 같은 요구사항을 구현하기 어렵다. 필요에 따라 직접 빌드하는 것도 괜찮은 것 같다.
- Virtual Thread는 LLM 호출처럼 I/O 대기가 긴 작업에 잘 맞는다. 별도 스레드 풀 튜닝 없이
Executors.newVirtualThreadPerTaskExecutor()한 줄로 쓸 수 있다. - 커스텀 마크다운 렌더러를 직접 구현할 때는 (사실 Claude Code가 구현해주었다 😅) LLM 출력의 실제 패턴(인덴트 서브 목록, 항목 사이 빈 줄)을 미리 파악하고 테스트 케이스를 충분히 준비하는 것이 중요하다.
소스 코드는 GitHub에서 확인할 수 있고, Demo Site는 이 웹사이트 메뉴에도 연결해놓았다. (Labs > Spring AI Ops)
