사내 공유하려고 예전에 썼었던 글인데 여기에 옮겨봅니다. 이 글에 언급된 아키텍처가 적용된 프로젝트는 사업 취소로 백지화 되어 서비스 오픈을 못하고 없어졌습니다. 🤣
애플리케이션 아키텍팅이란 무엇인가
소프트웨어 개발에서 가장 중요한 질문 중 하나는 “무엇을 만들 것인가”이지만, 그에 못지않게 중요한 질문은 “어떻게 만들 것인가”입니다. 이 “어떻게”에 대한 답을 찾는 과정이 바로 애플리케이션 아키텍팅(Application Architecting)입니다. 애플리케이션 아키텍팅은 단순히 기술 스택을 나열하거나 서버를 배치하는 그림을 그리는 작업을 의미하지 않습니다.
- 요구사항을 분석하여 도메인을 정의하고,
- 그 도메인을 데이터 모델로 구체화하며,
- 비즈니스 로직과 시스템 구조를 모듈 단위로 나누고 연결하는 과정을 포함합니다.
즉, 아키텍팅은 비즈니스 요구사항과 기술적 제약 사이에서 최적의 균형을 찾는 일입니다. 현재 개발 진행 중인 프로젝트에서, Back-End 애플리케이션 아키텍팅을 해 나갔던 과정을 소개합니다.
1. 이벤트 스토밍: 도메인 정의의 시작
프로젝트의 첫걸음은 회의실이 아니라, 제 모니터에 비춰진 Figma 기획 문서였습니다.
저는 개발자로서, 기획자가 정리해둔 화면과 요구사항을 꼼꼼히 읽어가며 이벤트 스토밍(Event Storming)을 진행했습니다.
“사용자가 장비를 등록한다.” “플랫폼에서 데이터를 제공한다.” “알림을 푸시한다.”
이처럼 기획 문서 속 시나리오를 사건(Event)으로 추출하면서 시스템 안에서 실제로 일어나는 일을 정리했습니다.
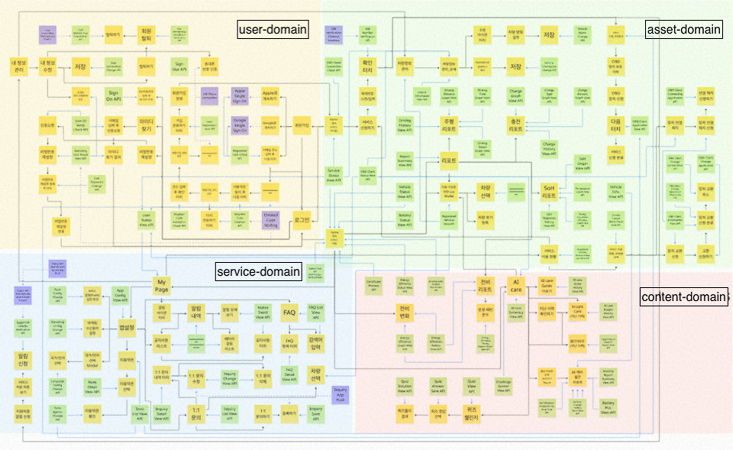
그 결과, 자연스럽게 네 가지 도메인이 드러났습니다. User, Asset, Service, Content. 이들은 프로젝트의 핵심 뼈대가 되었고, 이후 데이터베이스와 애플리케이션 구조의 출발점이 되었습니다.
2. 데이터베이스 설계: DBA의 손끝에서
이벤트 스토밍을 통해 도출된 도메인과 이벤트들은, 이제 데이터를 담아낼 그릇으로 옮겨져야 했습니다. 이 시점에서 저는 백엔드 개발자의 역할을 내려놓고, 전문적인 영역을 담당할 DBA(Database Administrator)에게 설계 결과를 전달했습니다. DBA는 제가 정리한 이벤트와 도메인 정의를 기반으로 엔터티와 관계를 뽑아내는 작업을 시작했습니다. 그 과정은 단순히 테이블을 나열하는 일이 아니었습니다.
먼저 논리 모델링(Logical Modeling) 단계에서 다음과 같은 사항을 중점적으로 고려했습니다.
1. 도메인 간 관계 정의
- 한 명의 사용자는 여러 장비를 등록할 수 있다.
- 장비는 플랫폼과 연동되며, 해당 장비와 관련된 콘텐츠가 제공된다.
- 플랫폼은 사용자별 맞춤형 데이터를 다시 콘텐츠로 가공한다.
이런 관계들이 일관성 있게 표현되도록 ERD(Entity Relationship Diagram)로 시각화했습니다.
2. 정규화(Normalization)
데이터 중복을 최소화하고, 변경이 있을 때 이상 현상이 발생하지 않도록 3차 정규형까지 고려했습니다. 예를 들어, 장비(Asset) 테이블에서 제조사 정보나 모델명은 별도의 레퍼런스 테이블로 분리해 관리할 수 있도록 했습니다.
3. 확장성 고려
처음에는 단순히 사용자와 장비만 연결하면 될 것 같았지만, 향후 장비 이력 관리, 콘텐츠 확장, 플랫폼 버전 관리 등 확장 가능성을 고려하여 스키마를 유연하게 설계했습니다.
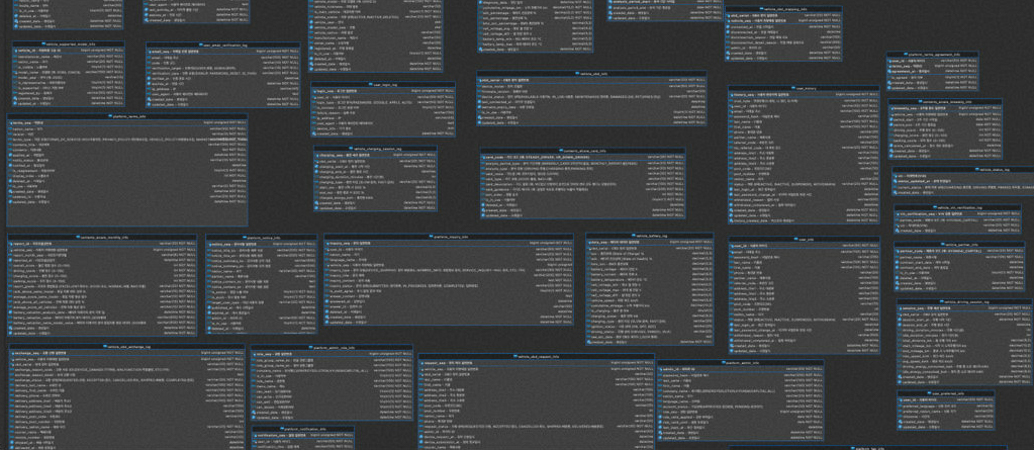
이렇게 설계된 논리 모델은 이후 실제 운영 환경에 맞춰 물리 모델링(Physical Modeling) 단계로 옮겨졌습니다.
물리 설계에서는 다음과 같은 결정이 내려졌습니다.
- 데이터베이스 엔진: 운영 환경은 AWS RDS(MySQL), 개발 환경은 H2 + MySQL 5.7
- 인덱스 설계: 사용자 ID, 장비 VIN 번호, 콘텐츠 키 값 등에 적절히 인덱스를 설정하여 조회 성능을 보장
- 외래키 제약(Foreign Key Constraints): 데이터 정합성을 강제하면서도, 트래픽이 몰릴 경우 성능에 영향을 주지 않도록 일부 관계는 애플리케이션 단에서 제어하도록 선택
- 샤딩·파티셔닝 고려: 초기에는 단일 인스턴스로 충분하지만, 장기적으로는 사용자 수와 장비 데이터가 기하급수적으로 늘어날 수 있기 때문에 수평 확장을 고려해 PK 설계를 진행
특히 DBA는 운영 환경에서의 트래픽 패턴을 염두에 두었습니다. 예를 들어, 장비 데이터는 한번 입력되면 수정 빈도가 낮지만 조회 요청은 빈번할 것이고, 반대로 사용자 세션 정보나 인증 토큰 관련 데이터는 갱신이 자주 일어날 것이라고 예상했습니다. 이러한 사용 패턴은 곧 인덱스 설계, 캐싱 전략, 데이터 파티션 기준으로 이어졌습니다.
결국 DB 설계는 단순히 테이블을 만드는 작업이 아니라, 도메인의 이벤트 흐름을 데이터로 굳히는 과정이었습니다. 백엔드 개발자인 제가 도메인을 정의하고, DBA가 그것을 토대로 실제 데이터의 형태와 운영 전략을 만들어 낸 것입니다.
3. 기술 스택 채택
다음 단계는 기술 스택을 고르는 일이었습니다. “Spring Boot 3.5.3을 쓰는 것이 적합할까요?” “Java 21의 Virtual Thread를 이번에 본격적으로 적용해봅시다.”
개발자들 사이에서 경험과 새로운 시도가 교차했습니다. 결과적으로 Java 21 + Spring Boot + Spring Cloud. 운영 환경은 AWS RDS(MySQL), 메시징은 AWS SQS, 서비스 게이트웨이는 기존의 Spring Cloud Gateway에서 Apache APISIX를 도입하기로 결정하였고, 서비스 디스커버리는 레퍼런스가 풍부한 기존의 Netflix Eureka로 정리되었습니다. 또한 우리 개발자들의 기술 역량을 축적하고 Java와 견주어 장점을 흡수하기 위한 목적으로 Kotlin 언어를 혼용하기로 하였습니다.
| 구분 | 스택 |
|---|---|
| 언어 & 프레임워크 | Java 21, Kotlin 1.9, Spring Boot 3.5.3, Spring Cloud 2025 |
| 데이터베이스 | H2 / MySQL 5.7 (로컬), AWS RDS (운영) |
| 메시징 & 서비스 | AWS SQS, Apache APISIX, Netflix Eureka |
| 캐시 & 모니터링 | Redis/Valkey, Micrometer / Prometheus |
이 결정은 단순한 신기술 도입이 아니라, 운영 효율성과 성능, 파트의 역량까지 고려한 실질적인 합의였습니다.
4. 멀티 모듈
초기에는 “MSA는 당연하고, 개별 모듈 구조로 가는 것이 더 빠르지 않을까?”라는 의견도 있었습니다. 그러나 장기적인 유지보수를 고려했을 때, 답은 분명했습니다. 멀티모듈 구조였습니다. 결과적으로 시스템은 다섯 개의 모듈로 구성되었습니다.
- 네 개의 도메인 모듈: Users, Assets, Platform, Contents
- 하나의 공통 모듈: Library
Library에는 인증, 예외 처리, 메시징, 캐시, 유틸리티와 같은 공통 기능이 포함되었습니다. 덕분에 도메인 모듈들은 독립적으로 유지될 수 있었고, 동시에 일관성을 확보할 수 있었습니다.
멀티모듈 채택 이유는 도메인 경계를 명확히 하면서, 재사용 가능한 컴포넌트를 분리하기 위함입니다. 이는 장기적으로 유지보수 비용을 낮추고, 팀 단위 병렬 개발에도 유리합니다.
5. 개발자의 작은 발상: @ParsedAuthToken
JWT를 다루면서, 개발자들은 늘 비슷한 코드를 작성했습니다. “토큰에서 userId를 추출하기.” 매번 몇 줄 안 되는 코드였지만, 모든 컨트롤러에 반복적으로 작성되어야 했습니다.
이 신규 프로젝트에도 그러한 일이 반복되어야 할까. 그러지 않기 위해 아이디어를 짜냈습니다. “애노테이션 하나로 userId를 꺼내 쓸 수는 없을까?”
이 생각은 곧 현실이 되었습니다.
@ParsedAuthToken이라는 애노테이션이 만들어졌고, 컨트롤러 메서드에서는 매개변수에 붙이는 것만으로 JWT에서 추출된 userId를 바로 활용할 수 있게 되었습니다.
@PostMapping("/notification")
public Rest<?> saveNotification(
@RequestHeader("Authorization") String accessToken,
@RequestBody NotificationRequest request
) {
// 수동으로 JWT 파싱 필요
String userId = tokenProvider.getUseridFromToken(accessToken);
platformService.saveNotificationInfo(userId, request);
return Rest.success();
}기존 방식
@PostMapping("/notification")
public Rest<?> saveNotification(
@ParsedAuthToken String userId, // JWT에서 자동으로 userId 추출
@RequestBody NotificationRequest request
) {
// userId에 이미 파싱된 사용자 ID가 들어있음
platformService.saveNotificationInfo(userId, request);
return Rest.success();
}새로운 방식
여기에 AOP까지 결합하여 userId가 실제 DB에 존재하는지도 자동으로 검증했습니다. 결과적으로 코드는 단순해졌습니다. 인증 로직을 공통화하고 애노테이션 + AOP로 추상화함으로써, 보안 강화 + 코드 가독성 개선이라는 두 마리 토끼를 잡았습니다.
6. Java 21 Virtual Thread와 FeignClient
Java 21에서 도입된 Virtual Thread는 I/O 바운드 호출에 혁신적인 성능 향상을 가져옵니다. 우리는 FeignClient 호출에 Virtual Thread를 결합해 사용했습니다.
@FeignClient(name = "users-service", url = "${interface.endpoint.users}",
fallbackFactory = UsersClientFallbackFactory.class)
public interface UsersClient {
@GetMapping("/users/{userId}")
Rest<Users> getUserById(@PathVariable("userId") String userId);
}FeignClient 인터페이스 생성
@Component
public class UsersConnector {
private final UsersClient usersClient;
private final VirtualThreadRunner virtualThreadRunner;
public Users getUserById(String userId) {
return virtualThreadRunner.runInVirtualThread(() -> {
return usersClient.getUserById(userId).data();
});
}
}FeignClient 래퍼
@Service
public class PlatformService {
private final UsersConnector usersConnector; // FeignClient 래퍼
public void processUserData(String userId) {
// 가상 스레드에서 비동기로 실행되지만 동기 코드처럼 작성
Users user = usersConnector.getUserById(userId);
// 사용자 데이터 처리
processUser(user);
}
}기본 사용법
@Service
public class DataAggregationService {
public AggregatedData getAggregatedData(String userId) {
// 여러 API를 병렬로 호출 (각각 가상 스레드에서 실행)
CompletableFuture<Users> userFuture = CompletableFuture.supplyAsync(
() -> usersConnector.getUserById(userId));
CompletableFuture<Asset> assetFuture = CompletableFuture.supplyAsync(
() -> assetConnector.getAssetByUserId(userId));
CompletableFuture<Content> contentFuture = CompletableFuture.supplyAsync(
() -> contentConnector.getContentByUserId(userId));
// 모든 결과 수집
return new AggregatedData(
userFuture.join(),
assetFuture.join(),
contentFuture.join()
);
}
}다중 API 호출 기존에는 스레드 풀 크기 조정과 자원 관리에 많은 노력이 필요했습니다. 그러나 Virtual Thread는 그러한 고민을 불필요하게 만들었습니다. 동기 코드의 가독성을 유지하면서도 비동기 성능을 확보할 수 있는 환경이 마련된 것입니다.
Virtual Thread는 단순 성능 최적화가 아니라, API 호출 패턴 자체를 바꾸는 아키텍처적 변화였습니다.
7. 코딩 컨벤션 정의
또한 백엔드 파트 차원에서 명명 규칙과 코딩 컨벤션을 정립했습니다.

- get, save, update*와 같은 레이어별 메서드 네이밍 패턴
- 카멜 케이스 일관성 유지
- 도메인 용어 통일
이런 작은 규칙들이 모여 파트 전체의 생산성과 유지보수성을 크게 끌어올렸습니다.
8. 메시징 솔루션 선택: AWS SQS
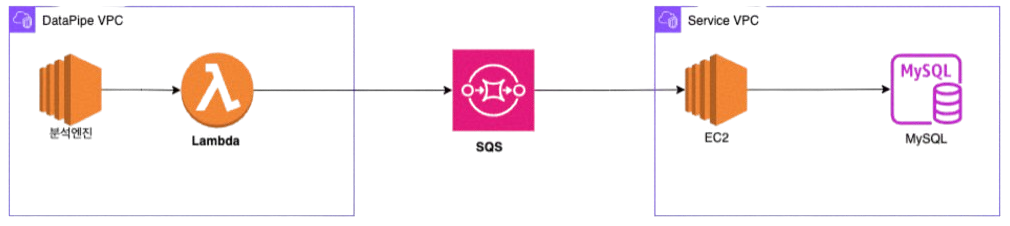
- Kafka: 강력하지만 운영 복잡성이 부담
- Redis Stream: 빠르지만 메모리 비용 고려 필요
- SQS: 완전 관리형, 자동 스케일링, DLQ 지원
운영 효율성과 개발 속도를 고려했을 때, SQS가 가장 적합했습니다. 특히 AWS SDK와 함께 사용하면서, SpringBoot에서 메시지 기반의 비동기 처리를 쉽게 구현할 수 있습니다.
저 개인적으로는 Kafka를 사용하기를 원했지만, “우리는 메시지 브로커를 직접 운영하는 것이 아니라, 서비스를 만드는 것이 목적입니다.” 이 말을 되새기며, 아쉬움을 뒤로 하였습니다.
9. 기술 워크샵에서 완성된 그림
마지막 단계는 기술 워크샵이었습니다. 성수동의 어느 거점 오피스에 개발자들이 모여 화이트보드에 아키텍처 다이어그램을 그리며 서로 질문을 던지고, 반박하며, 다시 고쳐 나갔습니다.
- Virtual Thread를 전 서비스에 적용할 것인가, 특정 계층에만 한정할 것인가
- 인증 책임을 어디까지 공통 모듈로 가져갈 것인가
- 메시징을 단순 큐 기반으로 운영할지, 이벤트 버스 형태로 확장할지
때로는 뜨거운 토론이 되었고, 때로는 웃음 섞인 대화가 이어졌습니다. 그 자리에서 완성된 아키텍처는 하나의 선언과 같았습니다. “자, 이제 이 아키텍처로 갑니다.”
10. 최종 아키텍처
최종적으로 확정된 아키텍처는 다음과 같습니다.
- 클라이언트 레이어: 모바일 앱, 백오피스 클라이언트
- API Gateway 레이어: Apache APISIX
- Service Discovery: Netflix Eureka
- 서비스 레이어: User, Asset, Service, Content
- 데이터 레이어: AWS RDS (MySQL)
- 메시징 레이어: AWS SQS + Consumer
- 공통 모듈: 인증, 유틸리티, 예외 처리
아키텍처는 도메인 중심, 이벤트 기반, 최신 JVM 기능 활용이라는 세 가지 축을 기반으로 구축되었습니다. 적지 않은 고민과 토론, 시행착오와 합의가 녹아든 결과물입니다.
마치며
아키텍팅은 단순한 기능 개발이 아닌, 도메인 정의 → 데이터 모델링 → 애플리케이션 구조 설계로 이어지는 엔드-투-엔드 엔지니어링 여정이었습니다.
특히 주목할 점은:
- 이벤트 스토밍 기반의 도메인 정의
- 공통 모듈과 애노테이션 기반 인증
- Virtual Thread 기반의 고성능 API 처리
- AWS SQS 중심의 Event Driven Architecture
이 네 가지가 결합되며, 확장 가능하면서도 유지보수 가능한 백엔드 아키텍처가 완성되었습니다. 이는 앞으로 더 많은 프로젝트에서도 반복될 우리의 방식이 될 것입니다.
