들어가며

지난 3월 27일, 롯데호텔 월드에서 열린 '2026 제조 고객을 위한 AWS 파트너 AI 클라우드 솔루션 컨퍼런스' 에 하루 종일 참석했다.
AWS와 ETEVERS가 공동 주최한 이 행사는 Keynote 4개에 3개 Track으로 구성된 총 22개 세션 규모였고, 나는 오전 전체 Keynote를 들은 뒤 오후에는 Track 1(Smart Manufacturing) → Track 2(AX Strategy) 순으로 이동하며 총 11개 세션을 직접 들었다.
내가 현재 담당하고 있는 시스템은 배터리 제조사에서 스핀아웃한 플랫폼 서비스이다. 제조 AI나 Physical AI가 주요 주제인 컨퍼런스여서 결이 조금 다를 수 있겠다 싶었는데, 실제로 들어보니 절반은 참고용, 절반은 지금 서비스에 바로 쓸 수 있는 이야기 였다.
- 컨퍼런스 전반의 제조 AI 트렌드 흐름
- 핵심 인사이트 — AI Observability (Datadog + Dynatrace)
- 현대오토에버 디지털 트윈 안전 사례
- 플랫폼 서비스 엔지니어 관점에서의 시사점
1. 제조 AI 트렌드

컨퍼런스를 관통하는 키워드는 세 가지였다. Physical AI, Digital Twin, Agentic AI.
Physical AI: 로봇이 소프트웨어가 되는 시대
숫자부터 보면 임팩트가 있다.
- 전세계 공장 가동 중 산업 로봇 430만 대 → Physical AI로 제어
- 2030년까지 미국 제조업 미충원 일자리 210만 개 전망
- 셀프 힐링 AI 5년 내 제조 현장 표준화 예상
- 2050년까지 휴머노이드 로봇 시장 5조 달러(USD) 규모 전망
"BYD는 이미 생산시설에 휴머노이드를 도입했고, 많은 기업이 직접 견학을 갔다. 미국은 로봇을 하드웨어가 아닌 소프트웨어로 보고 있다."

Sony는 AWS Nova Forge로 자사 전용 AI 모델(Novella)을 구축했다. 범용 AI로는 도메인 전문성에 한계가 있어서, 직접 파인튜닝을 통해 '우리만의 AI'를 만든 사례다. 리뷰·평가 효율 100배 향상이 목표라고 했다.
Amazon Robotics의 Cardinal 로봇은 비전 + Physical AI를 결합해 출하 물량의 70%를 로봇이 처리하는 수준까지 왔다. 도입 2년 내 대규모 운영 확산, 작업자 부상 위험 대폭 감소라는 성과를 냈다.
Digital Twin: 공장을 소프트웨어로 정의한다
Tesla의 Unboxed Manufacturing Process가 화제였다. 차세대 EV 및 휴머노이드 생산을 위한 완전히 새로운 제조 방식으로, 핵심은 Software-Defined Factory — 하드웨어를 소프트웨어로 정의한다는 개념이다. 목표는 70~80% 자동화, AI 주도, 소프트웨어 고도화.
Siemens가 제시한 휴머노이드 Digital Thread 개념도 흥미로웠다.
- Digital Genesis: 휴머노이드 개발 및 엔지니어링 (개념이 지능을 얻는 단계)
- Autonomous Production: 휴머노이드 양산 제조 (디지털 지능이 물리적 현실로)
- Coexistence Loop: 휴머노이드 운영 및 학습 (인간과 기계가 함께 진화)
SK AX의 IT Backbone 재설계 발표도 눈에 들어왔다.
| AS-IS (현재) | TO-BE (목표) |
|---|---|
| Silo식 생산시스템 | 전사 개방형 제조 플랫폼 |
| 거대하고 복잡한 소스 구조 | 모듈화, 간소화 |
| 복잡한 데이터 구조 | Single Data Access 체계 |
| 사람에 의한 판단 | Rule 기반 판단 |
| Monolithic 구조 | Micro Service (MSA) |
제조가 아닌 플랫폼 서비스여도 맥락은 같다.

Agentic AI & 도입 실패 교훈
제조 분야 AI 시장은 CAGR 45.6%, 2028년 208억 달러 전망이다. GS네오텍 세션에서는 흥미로운 통계를 제시했다.
산업·제조 기업 AI 도입 80%가 실패한다.
실패 원인은 단순했다.
- 기술 도입 자체가 목적이 되어버림
- AI로 해결할 문제를 오해하거나 잘못 전달
- AI 훈련 데이터 부족
- 데이터 관리 및 AI 활용 인프라 부족
"기술적으로는 성공했으나 아무도 쓰지 않는 제품이 탄생한다"는 말이 딱 맞았다. AI를 도입하든, 뭘 만들든 비즈니스 문제가 먼저여야 한다는 교훈이다.
2. 핵심 인사이트 — AI Observability
이게 오늘 글의 핵심이다. Datadog과 Dynatrace, 두 세션 모두 같은 방향을 이야기했다.
핵심 메시지 5가지
① AI와 결합된 Application Observability
단순한 모니터링을 넘어, AI가 평소 운영 지표를 학습하고 이상징후를 자동 탐지한다. 알람 피로도(Alert Fatigue) 제거를 위한 AIOps — 수천 개의 알람을 연관 이슈로 묶어서 정말 중요한 것만 보여준다.
② 장애 판단은 이제 AI가 한다
장애가 발생하면 AI가 가설을 세워 근본 원인을 분석·추적한다. 수집된 이벤트와 데이터를 기반으로 자동 분석 (Bits SRE Agent). 사람이 로그 뒤지고 팀끼리 슬랙 핑퐁하던 시대가 저물고 있다.
③ 시스템 메트릭 + 비즈니스 데이터 연계
메트릭/로그/트레이스를 비즈니스 데이터와 연결한다. 시스템 상태가 매출·고객 경험에 미치는 영향을 AI가 상관관계 분석 및 예측한다. 예를 들어 결제 서비스 응답이 3초 느려졌을 때, 그게 실제 매출 손실로 얼마나 이어지는지를 실시간으로 보여준다.
④ 소스코드 리포지토리 연결 → AI가 코드 수정 제안
발견된 이슈를 GitHub AI에 연결, 성능 저하·장애 원인이 될 수 있는 코드를 찾아내고 개선 방법을 제안한다. 코드 수정 단계까지 자동 연결 (Bits Dev Agent). MCP를 통해 다른 LLM과도 연계 가능하다.
⑤ 이상 탐지 → 추론 → 행동 → 보고서 자동 산출
회사 양식에 맞춘 장애 분석 보고서를 AI가 자동 생성한다. 장애 개요 / 타임라인 / 근본원인 분석 / 즉시 조치 / 재발 방지 방안까지 포함해서. 사람이 분석하고 문서 만드는 시간이 수시간에서 수분으로 단축된다.

Datadog — AIOps 기반 시스템 운영
Datadog은 "Observability to Action" 이라는 컨셉으로 발표했다. 관찰에서 끝나지 않고 실제 행동까지 연결한다는 의미다.




AIOps 3단계 플로우
[1단계: 탐지] Watchdog
↓
ML로 평소 패턴 학습
이상 패턴 자동 탐지
알람 피로도 제거 (연관 이슈 묶음)
↓
[2단계: 분석] Bits SRE Agent
↓
수집 이벤트·로그·트레이스 기반 자동 분석
서비스 간 관계도(Dependency Map) 자동 생성
근본 원인(RCA) 자연어 요약
장애처리보고서 자동 산출
↓
[3단계: 조치] Bits Dev Agent + MCP
↓
GitHub 연결 → 원인 코드 자동 식별
코드 레벨 개선안 제시
MCP Server로 다른 LLM과 연계
터미널에서 AI Agent와 실시간 분석 대화비용 거버넌스
단순 성능 모니터링을 넘어 클라우드 비용 관리까지 다룬다.
- 비용 Spike/Anomaly 자동 탐지 → 즉시 알람
- 태그별(서비스·팀·생성자) 비용 인사이트
- 전일/전주/전월 대비 증가율 및 예상 비용
- 미사용 EBS 볼륨, OverSizing EC2 자동 식별
- Bits Assistant AI로 이상 비용 근본 원인 분석
"리소스 최적화는 단순히 줄이자는 이야기가 아니다. 사용하지 않는 유휴자원이나 낭비되는 부분을 찾아 잘 활용할 수 있게 하는 것이 목표"라는 말이 인상적이었다.
운영 & 비즈니스 연계
Datadog의 AI Agent는 운영 데이터와 비즈니스 데이터를 이어주는 인터페이스 역할을 한다. 애플리케이션 장애가 났을 때 비즈니스 쪽에도 영향을 미치는 부분이 있는지 실시간으로 시각화한다.
Agent Builder(Preview)를 활용하면 다양한 시나리오를 구성해 일별 이슈 분석 리포트를 자동 생성하고 메신저/이메일로 주기적으로 발송하는 것도 가능하다.

Dynatrace — AI 도입 3단계
Dynatrace 세션은 초반에 소개한 현장의 목소리가 공감됐다.
- "AI는 좋은데 활용이 너무 어렵다"
- "데이터는 많은데 결국 사람이 분석해서 작업을 진행한다"
- "일만 많아지는 거 아냐?"
그리고 이 한마디가 전체 세션을 관통했다.
"가장 좋은 대시보드는 전문가의 얼굴이다."
AI가 그 전문가 역할을 대체하겠다는 것이다.
기존 모니터링 vs Observability

| 구분 | 기존 모니터링 | Observability + AI |
|---|---|---|
| 질문 | 무엇이 잘못됐는가 | 왜 잘못됐고 어떻게 개선하나 |
| 대응 | 알람 → 사람이 판단 | 알람 → AI 분석 → 솔루션 자동 제시 |
| 가시성 | 각 팀이 자기 영역만 확인 | 전체 서비스 관계도 통합 가시성 |
| 데이터 활용 | 데이터는 많지만 정보화 역량 부족 | 즉시 인사이트로 변환하는 AI |
AI 도입 3단계
1단계 — 연결(Connect)

Agent 설치만으로 SRE 환경이 즉시 구축된다. 서비스 간 관계도(Topology)가 사람 개입 없이 자동으로 그려진다. 데이터가 저장되는 순간 서로 자동으로 연결된다. 개발자가 수동으로 아키텍처 문서를 그리지 않아도 된다.
2단계 — 이해(Understand)

장애 감지부터 원인 구간 제시까지 즉각 자동 분석한다. 여러 서비스가 얽힌 복잡한 시스템에서도 문제 구간을 빠르게 식별한다. 발표에서 발주시스템 사례를 직접 데모로 보여줬는데, 복잡한 관계도 속에서 문제 지점을 1분도 안 돼서 찾아내는 걸 봤다.
3단계 — 행동(Act)
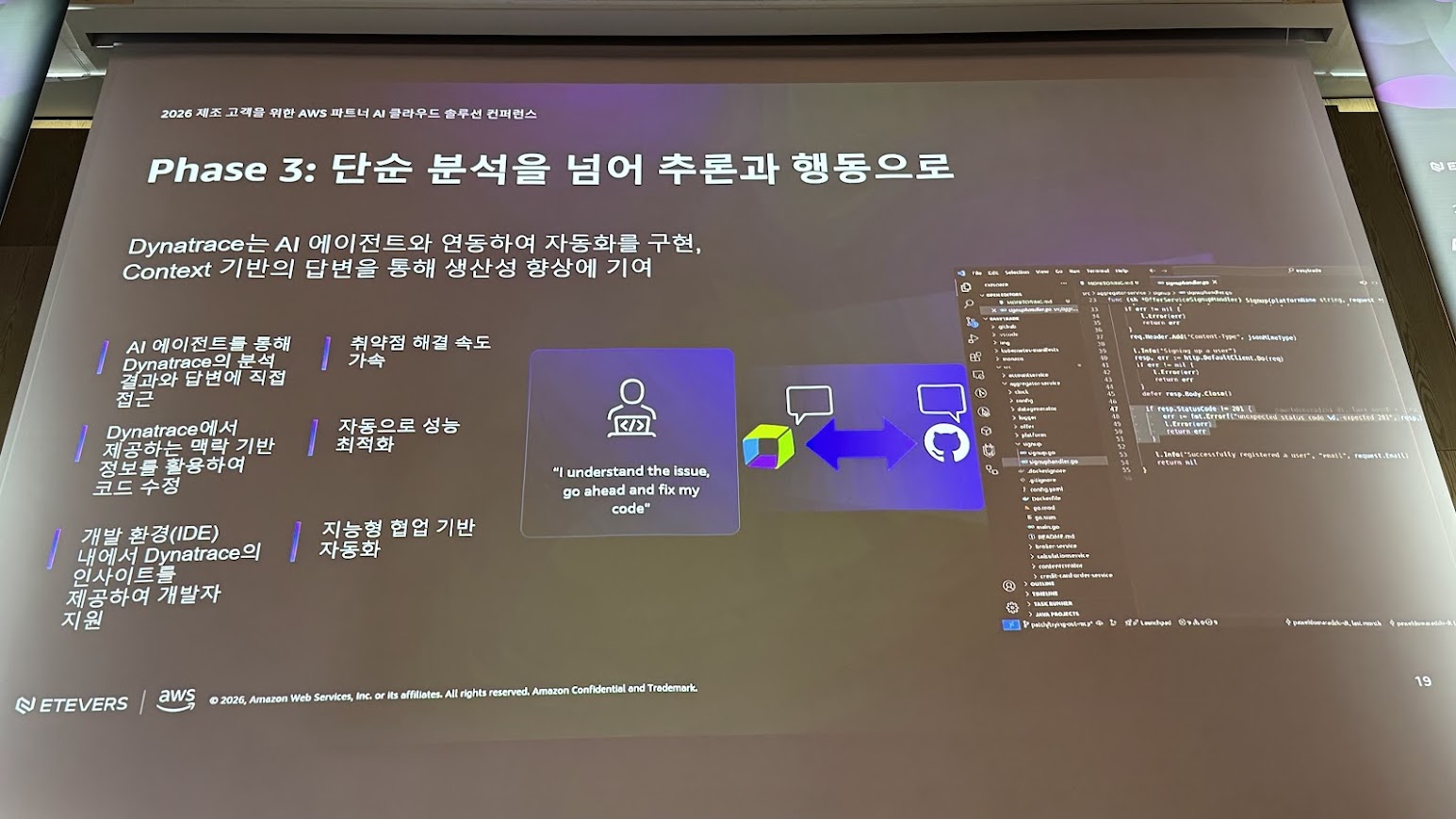
MCP를 통해 다른 LLM과 연계해 문제를 분석한다. GitHub AI에 연결해서 코드 수정 방법을 제안한다. 항공사 키오스크처럼 IT 외의 데이터도 분석에 활용 가능하다. AWS AmazonQ와도 완전 연동, 파이프라인 자동화를 구현할 수 있다.
PT에서 마지막 말이 인상적이었다.
"다단계 추론을 통해 원인과 해결책을 분석해준다. 사람이 그것을 하는 시대는 지났다."

3. 현대오토에버 — 디지털 트윈 기반 스마트 안전 통합관제
제조 안전 쪽에서 인상적인 세션이었다.
배경: 중대재해처벌법이 만든 변화
중대재해처벌법 시행으로 제조 현장의 안전관리 의무가 대폭 강화됐다. 경영자 입장에서는 사고가 나면 형사 처벌까지 받는다. 세 가지 목표를 중심으로 시스템을 구축했다고 했다.
- 경영리스크 감소
- 인적 피해 최소화
- 중대재해처벌법 능동적 대응
핵심 기능 4가지
① AI 기반 최적 대피 경로 안내
중대재해 발생 시 AI가 실시간으로 최적 대피 경로를 계산한다. 핵심은 개인화 다. 사람마다 위치가 다르고, 장애가 발생한 구간도 다르기 때문에 같은 상황에서도 사람마다 다른 경로를 제시한다. 기존의 일괄적인 "비상구 방향으로 대피" 와는 차원이 다른 대응이다.
② 레이더 기반 위험구역 접근 차단
레이더 기술을 이용해 위험한 구역에 작업자가 접근하는 순간 자동으로 감지하고 차단한다. 물리적인 울타리 없이 소프트웨어로 안전 구역을 설정하는 개념이다.
③ 디지털 트윈 가상 순찰
위험한 구역을 사람이 직접 가지 않고, 디지털 트윈 공간에서 실시간으로 모니터링한다. 이상 징후가 감지되면 현장과 실시간으로 소통하며 즉각 대응한다. 야간·위험 환경에서도 24시간 안전 모니터링이 가능하다.
④ 클라우드 기반 AWS AI 서비스 연계
제조업은 보통 폐쇄 네트워크 환경이 많다. 하지만 PUBLIC 환경에서는 AWS AI 서비스를 적극 활용해 예측 분석으로 사고 발생 전에 선제적으로 대응한다. SDF(Software Defined Factory) 전환 프로젝트와도 연계된다.
발표자가 강조한 한 마디.
"단순한 '감시'를 넘어 '통찰'을 제공한다. 사고를 예측하고 선제적으로 차단하는 것이 목표다."
4. 플랫폼 서비스 엔지니어 관점에서의 시사점
솔직히 말하면, 컨퍼런스 주제의 절반은 내 업무와 직접적인 관련이 없다. Physical AI나 제조 현장 안전 시스템은 배터리 제조 모회사에는 중요한 이야기지만, 플랫폼 서비스 입장에서는 '이런 세계가 있구나' 수준이다.
하지만 Observability 쪽은 다르다.
AI Observability
Datadog과 Dynatrace 모두 보여준 핵심 가치는 다음과 같다.
기존 SRE 스택:
수집 → 저장 → 시각화 → (사람이 판단) → 조치
AI Observability 스택:
수집 → 저장 → 시각화 → AI 자동 분석 → 솔루션 제시 → (사람이 확인) → 조치사람의 역할이 "판단하는 사람"에서 "AI가 제안한 것을 검토하는 사람"으로 바뀐다.
비즈니스 메트릭 연계 대시보드
서비스 장애가 서비스 해지나 CS 문의 증가로 이어지는 상관관계를 시각화하는 것을 해보고 싶다. 기술 지표로만 이야기할 때보다 비즈니스 영향도를 같이 보여줬을 때 의사결정 속도가 훨씬 빠르다는 걸 Datadog 세션에서 다시 한번 확인했다.
AI 기반 코드 품질 자동화
GitHub Actions + Observability 연동으로, 배포 이후 성능 저하가 감지될 때 AI가 관련 커밋을 자동으로 식별하고 개선 방향을 제시하는 체계. Spring Boot 4 / Kotlin 환경에서 어떻게 연결할 수 있는지 좀 더 알아봐야 할 것 같다.
마무리
하루 동안 컨퍼런스를 들으면서 든 생각은 하나였다.
AI가 운영 엔지니어의 역할을 바꾸고 있다.
장애 판단, 근본 원인 분석, 보고서 작성. 이것들이 하나씩 AI로 넘어가고 있다. Dynatrace 발표자의 말처럼 "사람이 그것을 하는 시대는 지났다"는 게 과장이 아닌 현실이 되어가고 있다.
우리가 해야 할 일은, AI가 잘 작동할 수 있도록 데이터를 잘 연결하고, AI가 제안하는 것을 올바르게 검토하는 역량 을 갖추는 것이 아닐까 생각한다.
내년 컨퍼런스에서는 "우리가 이렇게 적용했다"는 이야기를 쓸 수 있으면 좋겠다.
